Engineering At Samsara
How Samsara Built Data Transformation Pipelines to Manage Terabytes of Data
April 14, 2021

Big Data has been a popular buzzword in the world of computing for a number of years. However, sometimes I feel like it gets misinterpreted. People’s brains immediately jump to the idea of mass quantities of data across varying sources in different formats. Although this is one side of it, the more important side is accessing and analyzing the data. How can one unlock insights and make data-informed business decisions when the sheer amount of data is overwhelming?
At Samsara, we have over a million devices deployed to vehicles across the world. These devices send billions of data points to the Samsara Cloud every day. We capture all kinds of data; from how long a vehicle is on cruise control to the amount of pressure in a water tank on an industrial site. This adds up to terabytes of data that needs to be combed through in order to develop features and gain insights for our customers.
Our Data Platform team is responsible for powering our analytics and reporting infrastructure. We move Samsara data from the real-time production backends that power our live dashboards, into our data warehouse. Our data warehouse is a Spark platform built on AWS. For data persistence, we utilize Delta Lake, a storage layer that brings ACID transactions to Spark. Delta gives us the reliability and scale we need for performant querying across our data. A key function of our team is building tools on top of our data infrastructure that accelerate data product development for other teams. We recently finished a new tool to build Data Transformation Pipelines which I am going to dive into in this post!
Transforming All the Data
A lot of questions that analysts, data scientists, and engineers want to answer can’t be accomplished with a single, simple SELECT statement. This leads to large notebooks or multi-hundred line SQL files with dozens of queries being developed. When someone figures out a nice bit of analysis, it gets copy-pasted to a half-dozen other queries, often with minor tweaks along the way. This can rapidly lead to queries that are hard to debug or edit with sprawling, subtle data inconsistencies. We decided to provide Samsara with a framework for decomposing data transformations into a series of pipeline steps with verbose dependencies and version-controlled SQL.
Data Pipelines
The data structure used to model data pipelines is a Directed Acyclic Graph (DAG for short). In Data Pipeline talk, the edges of the graph represent data dependencies. Within the context of Samsara, these data transformations form the backbone of some high level customer-facing data product. We want the creation of data transformations and pipelines to be easy for our developers to use, as well as low overhead for our team to manage.
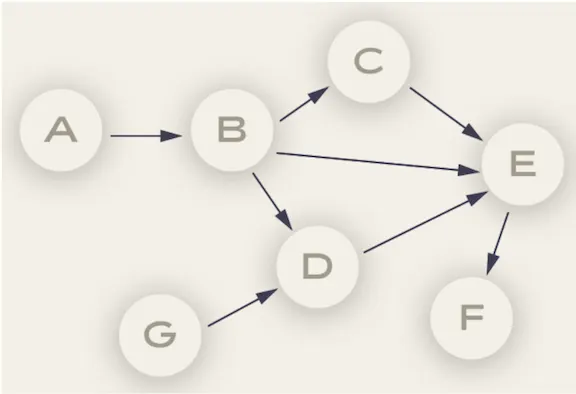
Design
From a high level, the design involves three major components:
A user experience that makes it easy to define transformations and data dependencies
An executor that runs transformations and persists data
An orchestration layer on top that manages scheduling transformations
User Experience
We want to make things as developer-friendly as possible while also putting all the power in their hands to create any sort of data transformations. Therefore, we prioritize creating a Domain-Specific Language (DSL) to define nodes and string pipelines together. By defining a DSL for our data transformations we aren’t tied to any one specific infrastructure. If we want to change the executor or orchestration engine we don’t have to redefine our pipelines, we just have to redefine how we deploy them. The DSL needs to be lightweight and easy to use.
Executor
We use Spark & Delta Lake extensively at Samsara for large scale data analysis. After someone has strung together some SQL transformations, the framework provides the underlying infrastructure to run the transformations on Spark clusters and persist their newly transformed data to our data lake for easy access to analyze or build data product on top of.
Orchestration Engine
The most complex piece of the puzzle was finding an orchestration engine to manage the pipeline workflow and data dependencies. Most open source solutions are great in their own right, the biggest downside for each was the deployment and management of the tools themselves. We also considered AWS Step Functions (SFN) which allow you to author workflows as state machines that call other AWS services. SFN provides all the pieces we need and operates in a purely serverless fashion, removing the deployment and management overhead. SFNs are JSON defined state machines consisting of states. These states can do anything from call a lambda function to pausing execution of the state machine for a configurable amount of time. This flexibility was incredibly appealing because, if built on this, our data transformation framework could be extended to many more types of nodes and functionality. After some playing around in the Step Functions builder UI we decide to move forward with it as our orchestration engine.
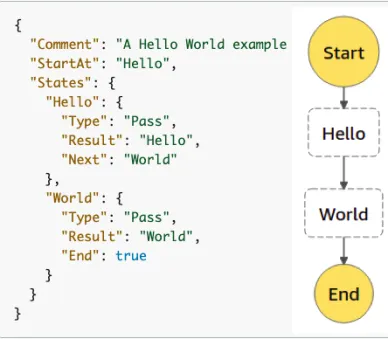
Implementation
To give you a sense of how this works in practice, here is a simplified version of a pipeline that powers a number of customer facing reports. Fuel is one of our customers’ largest costs, so providing insights into how their organizations use fuel provides high value. We are able to do this by joining our low-level fuel usage data reported by devices inside vehicles with driver assignments, which map when a driver was operating a certain vehicle.
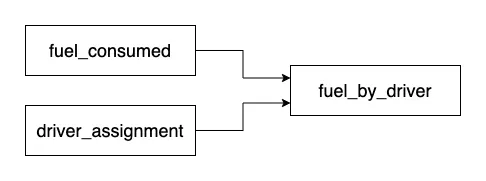
For each of these nodes in a pipeline, a developer would define an SQL file and a JSON file. The SQL file is the actual SQL that gets run on Spark clusters. The JSON file contains details about the transformation like how to partition it, the schema, and the dependencies of the transformation.
Go Engine
Go is one of the primary languages we use at Samsara. Therefore, we have a bunch of tooling for generating Terraform projects from Go. We were able to build on top of everything that our infrastructure team has already made to generate, test, and deploy all of the AWS infrastructure needed to run these pipelines with Terraform.
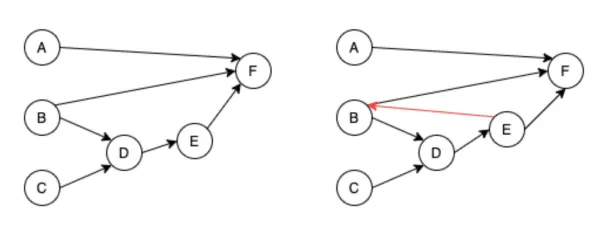
The Go engine is responsible for lots of validation of developer-defined data transformations. First, it validates the DAG contains no cycles and is not compromised before deployment.
Once we have built and validated the Global Pipeline DAG, we want to partition the graph into logical pieces for deployment to Step Functions. We partition the Global DAG starting from each leaf node.
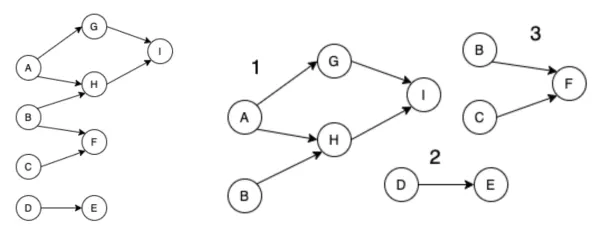
After these operations are completed and we have nicely partitioned DAGs, we are ready to deploy them to Step Functions!
Step Functions & Lambda
Once deployed, we use the power of AWS Serverless to execute the pipeline. Our example from the above deployed as a Step Function would look like:
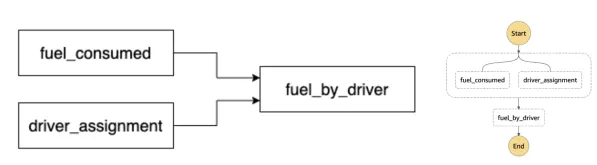
AWS Lambda Functions are the target Task within each of the states that takes the developer's transformation and runs it on Spark cluster within our Databricks environment. The results of the transformations are sunk into the Data Lake and the Step Function proceeds onwards because that specific transformation is done and all other transformations dependent on it can now be run.
DynamoDB & Dependency Management
If you take a look at the DAG partitioning example above, the B was present in multiple partitions. During deployment, this means that the same node would be in multiple step functions and executed multiple times per run. We circumvent this using a DynamoDB metastore to save the current state of our transformations.
Let’s create a new example. Let’s say we had this global DAG which the Go engine would split into two partitions:
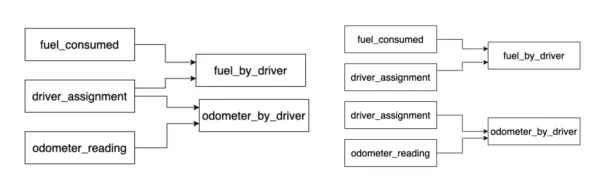
Notice that driver_assignment node is in both DAGs. This would then deploy as two separate Step Functions that look like:
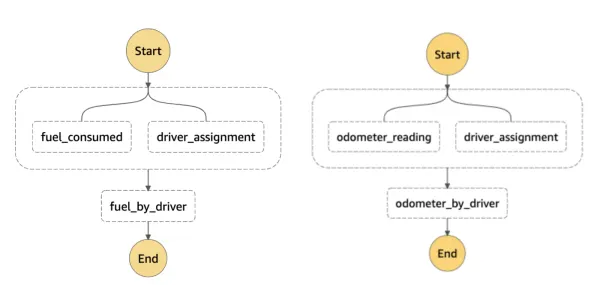
We don’t want to execute the driver_assignment transformation multiple times during a pipeline run. This is extra work and could also lead to race conditions when sinking data into the lake. During the Step Function execution, we first check the metastore to make sure the transformation is not already running. If we find it is running, continue to poll the metastore to see a COMPLETED status. If we find it not running, we load in a RUNNING entry, execute the transformation, and update the status to COMPLETED when done.
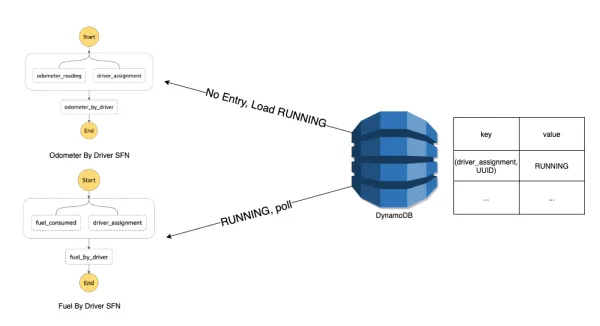
This use of dynamo as a global metastore and lock manager allows us to horizontally scale our pipelines by giving developers access to any transformation they may need when constructing their pipeline without having to worry about dependency management. They can add their nodes to their node configurations and all of this is handled by the underlying framework.
Final Product
We now have a fully managed data transformation framework that engineers, data scientists, and analysts can utilize to build their data transformations to develop rich insights into Samsara data. These types of data products allow Samsara to build next-generation features for our customers along with providing our data scientists with a platform to gain insights into our customers and the industry as a whole.
From an engineering perspective, the success of this project stems from the development of a DSL to define data transformations and the decision to utilize AWS Step Functions. The DSL creates a flexible and rich user experience and allows us to decouple the API from the underlying infrastructure. If we choose to move our framework to a different orchestration engine, we have our definitions and developers’ work won’t be lost. Choosing to build this with AWS Step Functions allowed us to leverage the power of serverless, iterate quickly, and avoid the headache of configuring and managing the low-level intricacies of the orchestration engine.
If this sounds interesting to you, we are hiring on our Data Platform team.
Read more

Building the First Industrial-Grade Asset Tag at Samsara

VP of Product & Engineering


How Samsara India’s R&D Team Will Transform Physical Operations and Your Career

VP of Engineering & India Site Lead







Improving CI/CD with a Focus on Developer Velocity

Senior Software Engineer