
Get the latest from Samsara
Subscribe nowBy: Brian Tuan, Sharan Srinivasan
On the Samsara machine learning and computer vision team, we build models and develop algorithms that help our customers improve the safety, efficiency, and sustainability of their operations. Depending on the particular product, the underlying models may reside in the cloud, be deployed to the edge, or even straddle both; in this post, we’ll discuss the models that run at the edge. Our CM31/CM32 series of dashcams, for example, run machine learning (ML) models in real-time — detecting potential hazards on the road and in the cab — to alert drivers and prevent accidents before they happen. These models are deployed in hundreds of thousands of vehicles today and help make the road a safer place for our customers and everyone else on the road.
From an engineering perspective, the safety-critical aspect of this product demands low latency ML inference on-device. Round-trip network latency and spotty cellular coverage eliminate the possibility of implementing these features in the cloud entirely. Thus, in addition to guaranteeing model accuracy, our team must also ensure that our models run within the stricter compute, memory, and latency bounds afforded by our edge hardware platforms.
In this blog post, we discuss the constraints posed by the environments our products are deployed in, analyze the tradeoffs that are considered when choosing models suitable for edge deployment, and deep-dive into some challenges that we’ve encountered in the process.
<a id="blog-inline-1" href="https://grnh.se/1bd958661us" title="Apply for open positions" class="btn btn--blue primary-btn">View opportunities</a>
Hardware, constraints, and acceleration
Our journey begins with the hardware platform. Federal regulation 49 CFR 393.60 stipulates that certain areas of a vehicle’s windshield may not be obstructed, so we cannot just fit a beefy desktop GPU into our dashcam to run state-of-the-art models. Correspondingly, our hardware team opted for a more compact (but compute-constrained) smartphone-based platform.
With this platform, we want to squeeze out every last drop of ML compute we can. Our firmware and embedded systems engineers help us do so by delegating certain tasks to specialized modules on our SoC — hardware video encoders/decoders, the ISP (image signal processor), etc. This leaves plenty of headroom on the CPU, GPU, and DSP (digital signal processor) for our models to run.
In general, CPUs are the least suited for our work (they tend to be power-intensive and slow), GPUs offer a good tradeoff of flexibility and parallel-computation throughput (but are power-intensive), and DSPs are extremely power-efficient and fast (but limited in flexibility). Each of these processor families bears implications on what kinds of models we can run on the device and the tradeoffs we need to make in order to do so.
Model selection and tradeoffs
As ML engineers, we’d love for nothing but to simply take the latest state-of-the-art model from CVPR and drop it into our devices: deep learning literature is rife with benchmarks set using heavy model backbones like VGG19 and ResNet152. However, these architectures can be orders-of-magnitude off from our latency requirements. Instead, we must principally consider the accuracy-latency tradeoff when selecting a model architecture as a starting point.
We turn to mobile-friendly architectures that are built with hardware acceleration and limited compute in mind. Among these, we’ve experimented with a few variants, including SqueezeNet, CaffeNet, and MobileNet. The depthwise-separable convolution introduced by the MobileNet paper, for example, factors the convolution operation to be more parallelizable and memory-efficient. This, along with other architectural innovations help reduce the model size, memory footprint, and execution latency while minimizing the impact on model accuracy.
Critically, we also have to understand how these architectures interplay with the on-device execution environment. While we train our models in many different autograd frameworks (mostly Tensorflow and PyTorch), we often have to translate the trained model artifacts to a format that the platform-level neural network execution engines can leverage.
This translation process is oftentimes beset with further challenges. Notably, many network layers (i.e. graph operations) are not supported by every deployment environment. Other layers, while supported, may not have corresponding hardware-accelerated implementations and thus force a subgraph to run on the CPU (consuming additional memory bandwidth and creating a CPU bottleneck). Each deployment environment has its own set of these idiosyncrasies: tflite supported ops, TensorRT supported ops, and SNPE supported ops all differ slightly. Some of these layer incompatibilities must be addressed during the training process by modifying the model architecture, and others must be addressed at the translation stage. We outline one approach for doing so below.
Graph surgery
Let’s say that we have a graph with an incompatible layer, and for some reason, we don’t want to — or can’t — modify the graph definition at train time. How can we still translate this model to be executed in our target deployment environment? Graph surgery based helps in this regard, by excising and stitching operations in a neural net computation graph to replace an incompatible operation with a set of supported ones (look ma, I’m a neurosurgeon!)
For this example, consider Keras’s GlobalAveragePooling2D layer. This layer is commonly used in image classifiers to pool the feature map of a convolutional feature extractor before those features are fed into the dense layers of a classification head. However, in the Tensorflow backend, this Keras layer is implemented as a tf.reduce_mean op, which is not supported by some of the aforementioned execution engines and not hardware-accelerated by others.
We can leverage the proto representation of the graph to excise the subgraph corresponding to the offending op and replace that subgraph with another single-input, single-output subgraph that has the same mathematical semantics but with different ops. Remember, in the end, a graph op is just a representation of a math operation!
(1a) original graph, incompatible op
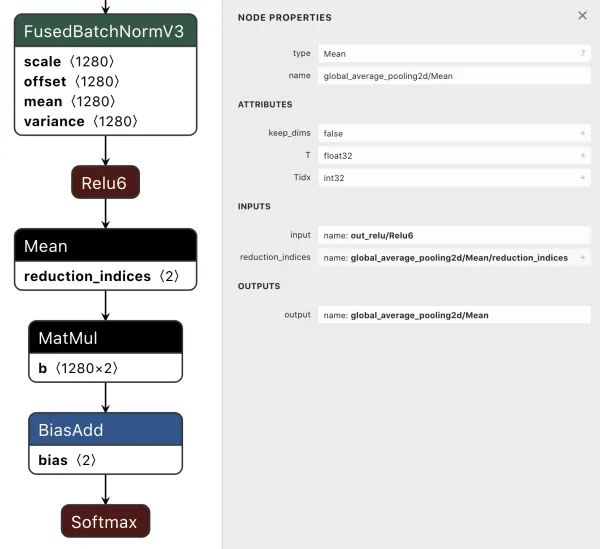
(2c) subgraph with replacement op
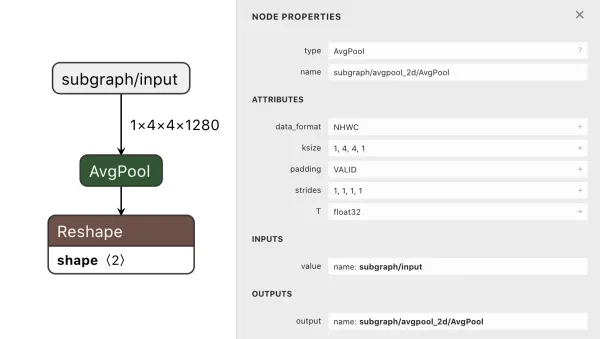
(3c) reconnected graph with replaced op


Let’s walk through these steps:
1. Identifying the subgraphs that need to be excised
a) In this case, we need to excise the tf.reduce_mean op and its associated metadata
b) Take note of the input and output names of this subgraph
2. Coming up with an alternate implementation of that op with other ops
a) This subgraph needs to take in the same input shape and output the same output shape as the tf.reduce_mean op, which means: input (1, 4, 4, 1280), output (1, 1280)
b) It looks like tflite supports average pooling (most frameworks should since it’s a very common CNN layer), so we can replace the reduce_mean with an average_pooling2d op having the same kernel size as the input (with no additional padding)
c) The shapes are not quite correct after the pool, so a call to reshape or flatten should make the output shape of this subgraph match the output shape of reduce_mean
3. Replacing the unsupported op with the replacement connected subgraph
a) Name the replacement subgraph nodes something sane, making sure there are no namespace collisions with the remaining graph, and insert it into the graph, connecting the input and output names to the remaining graph as necessary
b) Verify that the graph parses and is connected using a network visualization tool like Netron.
And there we have it! For most of the layer incompatibility issues we’ve encountered, we’ve been able to reimplement an unsupported op using the above trick. In some other cases, we’ve noticed that the graph conversion tools nominally support an op, but don’t necessarily the specific version of the op embedded in the graph. One example is the implementation of Tensorflow’s tf.add op was updated to tf.addV2 , causing some graph conversion tools to fail on pattern-matching the op name against the tool’s “supported” op names (like this). Yet, addition is still addition, so we can simply rename the op name in the graph proto to something that our converter can (AddV2 → Add).
Once we’ve completed the (sometimes arduous) task of exporting our trained model checkpoints to a platform-supported serialized graph representation and verified that the layers of the converted model are executed with hardware acceleration, we need to benchmark the model and compare the results with the latency requirements of the task. This part of the problem is well-explored by other literature: usually, the solution is some combination of removing or fusing operations, graph pruning, and quantization. We can remove all training nodes to slim down the graph size and fuse multiple operations (e.g. folding batch norm) using a graph transformation tool. For quantization, we’ve found that certain model architectures or variants suffer less accuracy drift than others and that the insertion of quantization nodes at training time helps ensure that post-training quantization induces less additional error on our validation set.
At this point, we’ve picked a hardware platform for our product, trained a model that is sufficiently accurate for our product needs, converted our model, and slimmed it down to run within the latency envelope afforded by our embedded code. This is just the tip of the iceberg! In later posts, our team will share additional implications and challenges related to running models both at the edge and in our cloud backend.
Interested in working on projects like this? Apply to our open positions! We’re always looking for great people to join us as we learn and grow together, and if you love learning and building things in a highly collaborative environment, we’d love to hear from you! 👋
<a id="blog-inline-1" href="https://grnh.se/1bd958661us" title="Apply for open positions" class="btn btn--blue primary-btn">View opportunities</a>
Get the latest from Samsara
Subscribe nowRead more

Behind the build: Smart Trailers and Connected Equipment at Samsara

Vice President of Product & Engineering, Connected Equipment

From idea to impact: Solutions built and shipped by our 2025 interns

Director, Firmware Engineering

Launch your tech sales career on Samsara’s ADR team

VP, Account Development

Building products that deliver real-world impact

Vice President, Product




Build for the Real World—Power A Safer, Smarter Future

Chief People Officer
