
Get the latest from Samsara
Subscribe nowSamsara had a large presence at last year’s Strange Loop. We set up a sponsor table where we got to meet some amazing developers and I had the opportunity to give one of the talks. In this blog post I’ll be diving into some interesting things I learned about Go’s compiler while I was working towards making our deploys faster.
Intro
At Samsara we use Go to power our Industrial IoT platform. When I say we use Go, I mean we really use it. A lot. For everything. I’m talking:
Backend services
Firmware that runs on our devices
Feature flags
Managing users & teams for things like github/aws/pagerduty/permissions
Generating Terraform files to codify the infrastructure that powers our services
Generating protobufs
Generating sql queries
Generating generators for sql queries
… and more

Deterministic deploys
We also used Go to write our deployment orchestration. In trying to improve our deploy speed, one of the projects we worked on was making our deployments byte-for-byte deterministic. This helps with our deploys by:
Reducing time spent moving docker layers across the network
Enables no-op deploys for unchanged microservices
Since we use a monorepo, changes to the repo trigger deploys for all services. Any way we can avoid doing a full deploy saves us time.
Saving on shutdown and startup time
Less downtime on singleton services. Services that we can only run one of at a time have a period of downtime until the new one comes up. The less this happens the better.
Prevention of initialization outages. Some outages are caused by things like config loading, bootup, etc. Minimizing startups allows services to run even in the event of a failure of any initialization dependencies.
These both led to a big improvement for us in deploy speed & reliability.
To get there, we had to:
Make Golang compiles deterministic
Make Docker builds deterministic
Reduce large dependency graphs
Golang has had some support for deterministic compiles since its 1.0, but for some reason our Go binaries were changing even when compiling the same code. While I was investigating why this was happening, I found an issue mentioning that the compiler’s determinism broke in Go 1.8beta. In this post, I’ll be diving into the developments that led to this regression in deterministic Golang compilation.
Static single-assignment form (SSA)
Go 1.7 introduced a new compiler backend based on static single-assignment form (also known as SSA).
SSA is a compiler design principle around structuring the intermediate representation so that every variable is assigned exactly once. In compilers the intermediate representation is the data structure or code used internally by a compiler or virtual machine to represent source code. Using SSA enables the Go compiler to:
Use some compiler optimizations it otherwise couldn’t have
Improve the performance of other compiler optimizations
Both of which lead to better performance for our Go code.
To read more about SSA I’d recommend reading the slides from one of Carnegie Mellon’s lectures.
Performance regression
While the SSA implementation was supposed to lead to better performance, it actually ended up degrading performance for a specific set of operations. Two divide operations ended up with about a 15% increase over the pre 1.7 compiler backend.
You can see the Github issue for this here.
The commit message for the fix says:
When allocating registers, before kicking out the existing value,
copy it to a spare register if there is one. So later use of this
value can be found in register instead of reload from spill. This
is very helpful for instructions of which the input and/or output
can only be in specific registers, e.g. DIV on x86, MUL/DIV on
MIPS.
Let’s break this down.
When allocating registers
Computer CPUs contain “registers,” which are used by the CPU to store data. Registers are the fastest place for CPUs to store data (faster than L1 Cache, RAM, & SSDs), and the CPU can only have a limited amount of them.
When a computer process needs to do an operation, such as division, it will often use registers to store the input and/or output of that operation.
before kicking out the existing value, copy it to a spare register if there is one.
If an operation needs to load data into a register before it can happen, it will need to move any existing data in that register somewhere else. Since there aren’t many registers, the compiler can choose to move it into RAM. Rather than just moving it to RAM, this change makes it try to move it to another register instead. This, however, makes the compiler more complex as it now has to deal with understanding which registers are holding data that is being actively used as well as clean them up after they no longer are.
So later use of this value can be found in register instead of reload from spill.
If we happen to need the data that was previously in the register, we can now read it from the register instead of from the “spill,” which is a term for data that has been moved from the register to RAM.
This is very helpful for instructions of which the input and/or output can only be in specific registers, e.g. DIV on x86, MUL/DIV on MIPS.
While some CPU operations can refer directly to a value in RAM, some, like the DIV (division) operation on x86 (a specific Intel CPU architecture), need to have those values in a specific register. If the value is currently in RAM instead of a register, it needs to first copy that value out of RAM into the register. Accessing RAM is much slower than accessing a register, which leads to the 15% performance loss we see.
Determinism regression
In addition to adding logic to copy registers instead of kicking them out to the spill, there needs to be logic to remove these copies if they end up never being used. While this fixed the performance regression, it also caused Go compiles to no longer be deterministic.
You can see the Github issue here: https://github.com/golang/go/issues/17288
The following is a snippet from the code that was added to fix the previous performance regression. Can you spot the issue?
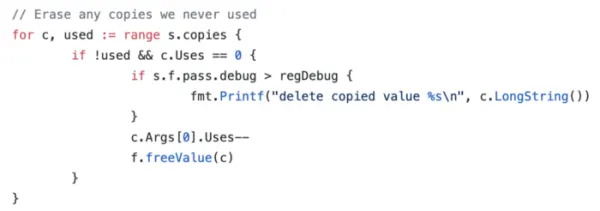
The first thing to understand here is what s.copies is.
// a set of copies we generated to move things around, and
// whether it is used in shuffle. Unused copies will be deleted. copies map[*Value]bool
But what is a Value?
// A Value represents a value in the SSA representation of the program.
// The ID and Type fields must not be modified. The remainder may be modified
// if they preserve the value of the Value (e.g. changing a (mul 2 x) to an (add x x)).
type Value struct {
...
// Arguments of this value
Args []*Value
...
}
You can see that s.copies is a map of SSA values and c.Args is a slice of other Values that are used as arguments to that value.
Going back to the code snippet, when freeing an unused register copy, we also decrement Uses for the first Argument.
What if c.Args[0] is actually a register copy itself?
The fix
Hopefully you might have an idea of what’s happening now, so let’s take a look at the fix.
One user in the issue thread asked an important question.
Do we make copies of copies? Is it possible that copy A is the only use of copy B, and depending on whether we visit A before B will influence whether we’re able to eliminate B?
He then implemented the following change.
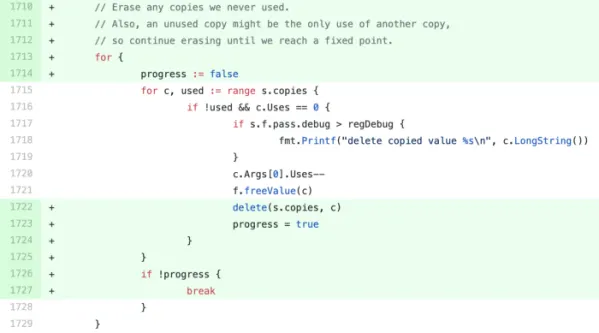
Rather than iterating through s.copies only once, we keep iterating through it until progress is false. progress will be true unless we don’t delete any copies in that iteration.
When calling c.Args[0].Uses — we may actually be freeing up another register copy, making it unused as well. Without the continued loop, this code can fail to erase an unused copy.
To illustrate this, let’s go through an example. Say we have two register copies, A and B. A is unused, whereas B is used but only as an argument to A. Let’s walk through two scenarios where the copies slice is ordered differently.
Scenario 1
s.copies = [A, B]
NOTHING -> A -> B (NOTHING uses A, but A uses B)
If we run through the code on the first iteration, we will determine that A is unused and erase it, leaving us with the following.
s.copies = [B]
NOTHING -> B (NOTHING uses B)
Continuing on to B as part of the iteration, we determine that B is unused and erase it, leaving us with the following.
s.copies = []
NOTHING -> (All copies have been erased)
Scenario 2
s.copies = [B, A]
NOTHING -> A -> B (NOTHING uses A, but A uses B)
If we run through the code on the first iteration, we will determine that B is still being used, and ignore it, leaving us with the same state.
s.copies = [B, A]
NOTHING -> A -> B (NOTHING uses A, but A uses B)
If we then continue on to A as part of the iteration, we will determine that A is unused and erase it, leaving us with the following.
s.copies = [B]
NOTHING -> B (NOTHING uses B)
You can see that we end up with different states, causing our broken determinism.
Fixed scenario 2
Let’s now add the fix to the equation and continue with the 2nd scenario. We are currently at the following state.
s.copies = [B]
NOTHING -> B (NOTHING uses B)
By running the entire algorithm again, we will see that B is unused and erase it, leaving us with the same state as the 1st scenario.
s.copies = []
NOTHING -> (All copies have been erased)

This fix was merged in 1.8beta1, and you can see the issue here.
Getting to deterministic builds
Since we were already on go1.10, it didn’t seem that this exact bug should have affected us, but I was wondering if it could have been re-introduced in another way.
It turned out, however, that the reason our compiles were non-deterministic was that Golang’s host linker includes a randomly generated build ID in its binaries.
To get around this, we ended up compiling our binaries with this not well-documented flag:
ldflags=”-linkmode=internal"
to use Golang’s internal linker, which does not include the build ID in the binary.
Working @ Samsara
At Samsara, we take pride in solving challenging problems and building the right solution, even if it means we might need to do a bit of digging.
Samsara is only about 5 years old, which means we use a lot of the latest technology. We’ve also scaled to over 100 Billion sensor data points collected yearly, which means we run into some interesting challenges that most other companies haven’t seen. If you’d like to help solve them, check out our open positions!
Get the latest from Samsara
Subscribe nowRead more

When AI brings your loved one home safe

Vice President of Artificial Intelligence

Join a world-class Customer Success organization

VP, Customer Success

Behind the build: Smart Trailers and Connected Equipment at Samsara

Vice President of Product & Engineering, Connected Equipment

From idea to impact: Solutions built and shipped by our 2025 interns

Director, Firmware Engineering

Launch your tech sales career on Samsara’s ADR team
VP, Customer Success

Building products that deliver real-world impact

Vice President, Product


